| CS-534: Packet Switch Architecture
Spring 2004 |
Department of Computer Science
© copyright: University of Crete, Greece |
3.2 Multi-Queue Data Structures
|
[Up - Table of Contents] [Prev - 3.1 Queueing Arch., HOL] |
[3.3 Multicast Queueing - Next] |
3.2.1 FIFO Buffer Memories




See Exercises 3 for a discussion of how large the segment (block) size should be.
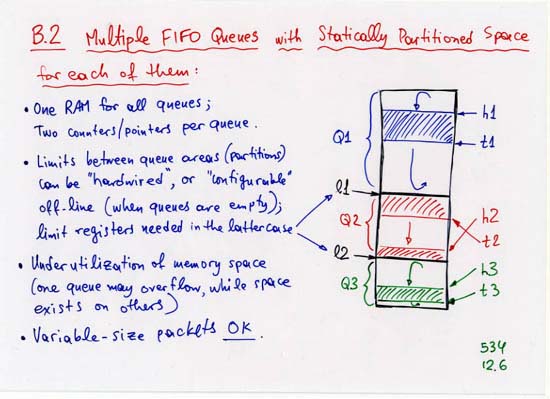
3.2.2 Multiple FIFO Queues Sharing One Memory

Notes:
-
(Portions of) Single or Multiple (variable size) Packets
per Block?
When variable-size packets
are kept in multiple queues in a buffer memory,
the usual systems only place only a single packet (or portions thereof)
in each block.
See exercise 5.1
for a very interesting alternative scheme
of Multi-Packet Block segmentation:
data from multiple packets can co-exist
inside a same memory block (segment).
-
Packet-Size information along with NxtPtr:
When packets have variable size,
we need to know their size, somehow.
This information usually appears inside the packet,
but the packet resides in the "DataMem",
which is often implemented using (slower) DRAM,
and we may need fast access to the size information.
The "nxtPtr" usually resides in SRAM,
so we may want to keep size information in that memory,
along with this pointer.
Here are three examples of possible configurations:
- The packet size may be recorded next to each nxtPtr. As an example, say that this size is always a multiple of 4 bytes, and the maximum size is around 9 KBytes ("Jumbo" frames); then we need 14-2= 12 bits of size information next to each nxtPtr. A typical size for the nxtPtr is around 24 bits, so this solution amounts to a 50% overhead for the nxtPtr memory.
- In several applications, the only information that is needed quickly (before reading the packet itself, hence its size as well, from the DataMem DRAM) is whether or not the current block is the last block of the current packet. This information can be encoded using a single bit next to each nxtPtr.
- A hybrid of the two previous solutions is to encode, next to each nxtPtr, the number of bytes in the current block that are occupied by the current packet, and whether or not this is the last block of the packet. For 64-byte segments and packet sizes that are multiples of 4 bytes, we need 5 bits for all this information: 4 bits are not enough, because all 15 values from 4, 8,... up to 60 bytes are legal values for the last block of a packet, plus "64 occupied bytes" corresponds to two valid states --intermediate block of a longer packet, or last block of a packet whose size happened to be a multiple of 64.



- This table assumes that all memory accesses shown on the previous transparency --both basic and exceptional-- have to be performed during each and every enqueue or dequeue operation. For the more "serial" implementations (fewer memories available), this may not be the case: the first access will often show whether we are in the normal or in the exceptional case, and the next accesses can then be tailored accordingly; see exercise 4.1.
- The table above assumes old-style off-chip SRAM, with fall-through timing: one-cycle latency for the entire off-chip access process, plus one more cycle lost on-chip between dependent accesses. See exercise 4.2 for a more aggressive case: synchronous (pipelined) off-chip SRAM (more cycles of latency but with a faster clock), and no extra cycle lost on-chip between dependent accesses.
- To achieve peak throughput, by overlapping successive queue operations, the latency of individual operations will often have to be increased.
- G. Kornaros, C. Kozyrakis, P. Vatsolaki, M. Katevenis: ``Pipelined Multi-Queue Management in a VLSI ATM Switch Chip with Credit-Based Flow Control'', Proceedings of ARVLSI'97 (17th Conference on Advanced Research in VLSI) Univ. of Michigan at Ann Arbor, MI USA, Sept. 1997, IEEE Computer Soc. Press, ISBN 0-8186-7913-1, pp. 127-144; http://archvlsi.ics.forth.gr/muqpro/queueMgt.html

Reference: A. Nikologiannis, M. Katevenis: "Efficient Per-Flow Queueing in DRAM at OC-192 Line Rate using Out-of-Order Execution Techniques", Proc. IEEE Int. Conf. on Communications (ICC'2001), Helsinki, Finland, June 2001, pp. 2048-2052; http://archvlsi.ics.forth.gr/muqpro/queueMgt.html

See also exercises 2.3, 2.4, and exercises 3 for discussions on access rate and segment (block) size.



|
[Exercises - 4. Linked-List Queues] [Prev - 3.1 Queueing Arch., HOL] |
[3.3 Multicast Queueing - Next] |
| Up to the Home Page of CS-534
|
© copyright
University of Crete, Greece.
Last updated: 16 Apr. 2004, by M. Katevenis. |